Recently I wanted to get some *BSD ELFs running on Windows - natively, and without crazy legwork (e.g. writing kernel drivers). The main goal was to simulate enough of the runtime environment such that I could comfortably debug the binaries (à la QEMU userspace emulation). After initial pondering, efforts required to accomplish this could be broken out:
- ELF parsing
- Module loading
- Dynamic linker
- .eh_frame translation
- libpthread compatibility
- Syscall translation
Some of these topics have likely been covered to death by others (ELF basics). However, this post will talk about some tricks I employed to make my simulator work which I haven't seen in actual use before.
Execution Environment
Guest: semi-recent amd64 CPU, BSD-style runtime.
Host: amd64 CPU, Windows 10 x64.
Solutions presented here rely explicitly on the details of the host and guest environments. Specifically:
- The CPU executing the simulated environment supports all instructions which the guest environment may execute.
- This restriction is just because it happened to be the case, and I had no reason to add support for other CPUs.
- Trapping the "illegal instruction" exception and simulating unsupported instructions in software would be an easy workaround - and of course could be improved, up to the point of writing a full dynamic recompiler.
- The host and guest methods of referencing thread-local data do not overlap.
- In this case, the guest uses
fswhile the host usesgs(andfsis effectively ignored).
- In this case, the guest uses
- The guest environment enforces strict W^X, and in fact does not allow modifying code at all*
- *JIT is allowed in edge cases, however it is well-defined, such that common pitfalls of simulating JIT'd code are avoided.
.eh_frame Translation
As I am familiar with debuggers for Windows, I decided to improve the debugging experience of dealing with guest code. The first step towards this is enabling the debugger to unwind the stack, thus showing proper stack frames and backtraces. Additionally, since DWARF and Windows both support it, this allows the debugger to restore spilled register values from the stack when viewing stack frames.
The process of parsing .eh_frame (and .eh_frame_hdr) is straightforward, however the conversion process requires some care. For the most part this is a side effect of dealing with the under-documented "FunctionTable" Windows APIs.
NOTE: All functions reference "init instructions" containing the following CFIs:
def_cfa(Rsp, 8)
offset(ReturnAddress,-8)
This serves to implement the standard amd64 ABI, and can effectively be ignored when converting to Windows-style, which always assumes these actions.
Consider the following guest prologue:
000002d7`908852e0 55 push rbp
000002d7`908852e1 4889e5 mov rbp,rsp
000002d7`908852e4 4157 push r15
000002d7`908852e6 4156 push r14
000002d7`908852e8 4154 push r12
000002d7`908852ea 53 push rbx
000002d7`908852eb 4883e4e0 and rsp,0FFFFFFFFFFFFFFE0h
000002d7`908852ef 4881ec80010000 sub rsp,180h
.eh_frame contains an FDE containing these instructions for it:
advance_loc(1)
def_cfa_offset(16)
offset(Rbp,-16)
advance_loc(3)
def_cfa_register(Rbp)
advance_loc(18)
offset(Rbx,-48)
offset(R12,-40)
offset(R14,-32)
offset(R15,-24)
The resulting frame can be summarized as:
[end of prolog]
-48 rbx
-40 r12
-32 r14
-24 r15
-16 rbp <- fp
- 8 saved rip
[caller frame]
At a high level, the most important information stored in the FDE is simply the stack displacement needed to find the previous frame, and the location at which the previous frame pointer was stored, if it was spilled. As you can see it also encodes locations of other registers as well as indicating the approximate native instruction displacement the register was spilled. As previously mentioned, getting this all to work in Windows' format requires some care.
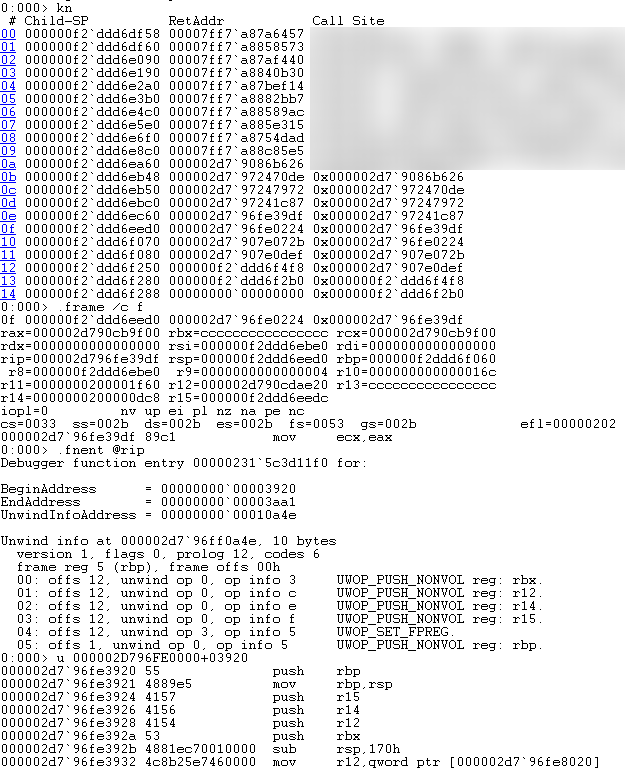
As it's easiest to explain by example, here is the generated Windows unwind info for the above function:
0:000> .fnent @rip
Debugger function entry 00000231`5c3d11f0 for:
BeginAddress = 00000000`000252e0
EndAddress = 00000000`000258e9
UnwindInfoAddress = 00000000`00087470
Unwind info at 000002d7`908e7470, 10 bytes
version 1, flags 0, prolog 16, codes 6
frame reg 5 (rbp), frame offs 00h
00: offs 16, unwind op 0, op info 3 UWOP_PUSH_NONVOL reg: rbx.
01: offs 16, unwind op 0, op info c UWOP_PUSH_NONVOL reg: r12.
02: offs 16, unwind op 0, op info e UWOP_PUSH_NONVOL reg: r14.
03: offs 16, unwind op 0, op info f UWOP_PUSH_NONVOL reg: r15.
04: offs 16, unwind op 3, op info 5 UWOP_SET_FPREG.
05: offs 1, unwind op 0, op info 5 UWOP_PUSH_NONVOL reg: rbp.
The rules to obey are simple, it was just annoying to figure most of them out by trial-and-error:
- "frame offset" value for Windows-style is the offset from the "current" value of the frame base.
- In other words, DWARF sets FP to an offset from the CFA symbolic value, while Windows sets it relative to the possibly-displaced value of RSP as it walks the unwind info.
- Order of registers being pushed must match the native instructions, even if
UNWIND_CODE.CodeOffsetis equal to other entries.- You'll notice that generated CFIs tend to list them in reverse order, per native instruction location.
- Failing to do this results in unwinding which appears to work most of the time (if FP is correct), but breaks on some edge cases.
- Perhaps some others which slip my mind at time of writing, but the above example should cover everything ;)
Finally, we can see it in action:
libpthread Compatibility
I came up with two methods of getting fs accesses from guest code to work transparently.
First, the complete-hack-but-working method:
enum SysarchOp {
kAMD64_SET_FSBASE = 129,
};
static u64 s_fsbase_hax;
static LONG CALLBACK ExceptionHandlerHack(PEXCEPTION_POINTERS ExceptionInfo) {
// TODO Should actually disasm to check if it's fs access.
// This check is enough to differentiate most pthread accesses, anyways...
uintptr_t accessed = ExceptionInfo->ExceptionRecord->ExceptionInformation[1] & 0xfff;
if (ExceptionInfo->ExceptionRecord->ExceptionCode == EXCEPTION_ACCESS_VIOLATION &&
(accessed == 0 || accessed == 0x10)) {
_writefsbase_u64(s_fsbase_hax);
return EXCEPTION_CONTINUE_EXECUTION;
}
return EXCEPTION_CONTINUE_SEARCH;
}
int Kernel::sysarch(int op, char *parms) {
printf("%s(%i,%p)\n", __func__, op, parms);
switch (op) {
case kAMD64_SET_FSBASE:
{
u64 a64base = *reinterpret_cast<u64 *>(parms);
printf(" AMD64_SET_FSBASE: %llx\n", a64base);
s_fsbase_hax = a64base;
AddVectoredExceptionHandler(FALSE, ExceptionHandlerHack);
break;
}
}
return 0;
}
Essentially, this relies on the guess that fs, as assigned by Windows, will point to unmapped memory. On any unhandled exception, ExceptionHandlerHack will make a lame attempt to verify the exception source was because fs was used. If so, it will use _writefsbase_u64 to update the actual fsbase register value (from usermode!) to point to the correct, mapped region. Execution then continues. This allows the modified fsbase value to be used until Windows resets the value. Reset will occur after Windows resumes thread execution for any reason (coming back from kernel, sleep, wait, etc).
Overall, this method is completely usable for test / bringup code.
The second method builds on the fact that Windows has assigned a static value to fs, is in fact unique per thread, and fairly predictable.
Let's inspect some code:
#include <thread>
#include <cstdint>
#include <cstdio>
#include <vector>
#include <Windows.h>
static void show_regs(const char *x) {
uint64_t fsbase = _readfsbase_u64();
uint64_t gsbase = _readgsbase_u64();
puts(x);
printf(" fsbase %16llx gsbase %16llx\n",
fsbase, gsbase);
}
int main() {
show_regs("main thread:");
DWORD grab_size = 0x100000;
auto p = (uint8_t *)VirtualAlloc(
(PVOID)_readfsbase_u64(), grab_size,
MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
printf("grabbed %p : %p\n", p, p + grab_size);
for (int i = 0; i < 10; i++) {
std::thread x([&]() {
char b[10];
sprintf(b, "thread %i:", i);
show_regs(b);
});
// keep execution sequential
if (x.joinable()) {
x.join();
}
}
return 0;
}
This outputs something like the following:
main thread:
fsbase eddf2000 gsbase eeeddf0000
grabbed 00000000EDDF0000 : 00000000EDEF0000
thread 0:
fsbase eddfa000 gsbase eeeddf8000
thread 1:
fsbase eddfc000 gsbase eeeddfa000
thread 2:
fsbase eddfe000 gsbase eeeddfc000
thread 3:
fsbase ede00000 gsbase eeeddfe000
thread 4:
fsbase edc02000 gsbase eeedc00000
thread 5:
fsbase edc04000 gsbase eeedc02000
thread 6:
fsbase edc06000 gsbase eeedc04000
thread 7:
fsbase edc08000 gsbase eeedc06000
thread 8:
fsbase edc0a000 gsbase eeedc08000
thread 9:
fsbase edc0c000 gsbase eeedc0a000
Just eyeballing it, some suspicious things can be seen:
fsbaseappears to be a truncated value closely tracking the value ofgsbase.- It's possible to own all memory which
fsbasevalues point to. fsbasevalues are displaced by 0x2000 per allocated thread.- In windbg,
?? sizeof(nt!_TEB), evaluates to 0x1838.
- In windbg,
In the above run, some fsbase values were below the value read from the main thread. As such, a full implementation of "stealing" the memory which Windows happens to set fsbase to is slightly more complex than allocating everything up-front, but it's not too challenging.
More context about the layout of allocations affecting fsbase values can be seen with !address in windbg.
For the simulator, this allows owning the memory which Windows forces fs to per thread. However, this value is unrelated to the value which simulated pthreads will attempt to set via the sysarch syscall (the value is likely some other allocation the guest code has allocated via a mmap syscall). Tying these two values together can be accomplished by something Raymond Chen considers a "stupid trick", but is used very effectively by clever, real-world code.
Both methods have their drawbacks, but I found them interesting and perfectly usable. :)
Syscall Translation
There's not much exciting to say about this. Execution is returned to simulator code by simply patching syscall instructions at the time of module load. At rutime the simulator determines which syscall was attempted to be executed and implements the syscall behavior itself. Proper thunking is used to translate ABI while still allowing unwinding by the debugger.
End
I hope these observations were useful to someone. If you have better ideas, feel free to drop me a line.